

Es geht langsam auf das Ende des Jahres zu und damit wird es auch wieder die Zeit, in der ich langsam auf meine Statistik schiele, wohl wissend, dass da bald viel Arbeit auf mich zukommen wird.
Denn ich Wahnsinnige habe mir da ein Monstrum an Statistik aufgebürdet.
Schon für 2018 bin ich weg von der reinen Goodreads-Statistik hin zu einer eigenen, die ich letztlich mit Stata auswerte, einem Statistikprogramm für quantitative Forschung, das zu bedienen ich in der Uni gelernt habe (und das ich für Bachelor- und Masterarbeit genutzt habe). Der Vorteil daran ist, dass man auch Kreuztabellen machen und Zusammenhänge untersuchen kann. Ich kann also das Programm quasi fragen: „Tage gelesen, wenn Variable Fantasy = Ja?“ Nur, dass es noch ein bisschen komplizierter im Code klingt.
Oder aber ich kann mir anzeigen lassen, ob ich Autorinnen oder Autoren besser bewerte und ob das Ergebnis nur Zufall ist, oder signifikant, also, ob daraus abzuleiten ist, dass ich mir Bücher von Autorinnen generell besser oder schlechter gefallen als Bücher von Autoren, oder, ob eine womöglich bessere Durchschnittsbewertung eines Geschlechts nur eben nur Zufall ist. (Wobei man für ein aussagekräftiges Ergebnis auch alle anderen Variablen (Länge, Genre, Entstehungszeit des Buches, …. mit einbeziehen muss, was es rein im Coding gleich deutlich schwerer macht.)
Jedenfalls wollte ich endlich mehr, als nur sehen, welches Buch das längste und welches das kürzeste ist, welches besonders oft oder besonders gut von Goodreads-Usern bewertet wurde. Ich wollte sehen, welche Autoren ich besonders oft lese, welche Reihen, welche Verlage.
Etwas Besseres muss her
Nachdem ich im letzten Jahr noch nicht allzu zufrieden mit meiner Statistik war, weil ich so etwas wie Repräsentation von Minderheiten nicht mit drin hatte, habe ich in diesem Jahr ein neues System ausprobiert. Ich wollte so viel wie möglich erheben. Und ich hatte keine Lust, das mühsam selbst in eine Tabelle einzugeben. Also griff ich zu Google Forms, wo ich je nach Frage teilweise nur klicken muss, und mir das System das hinterher selbst lustig in eine Tabelle umformatiert.
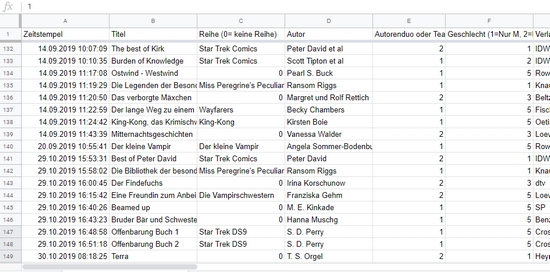
Wobei ich trotzdem gleichzeitig nur bei den Variablen nur die Möglichkeiten zur Beantwortung gab, die ich auch wirklich gebrauchen konnte. Bei den Genres konnte ich also Erotica zum Beispiel auslassen. Dennoch wurden es sehr viele Kategorien.
Ignoriert diesen Tweet, ich brauche ihn nur, um das Video in einen Blogbeitrag einzufügen, weil WordPress das offenbar nicht zulässt. pic.twitter.com/VJA07QkWNj
— #WeareStarfleet Baguette (@zwiebelbaguette) December 6, 2019
Die Sache mit der Faulheit
Und damit kam auch schon die erste Ernüchterung: Ich liebe zwar die Statistik, die ich am Ende basteln kann. Aber ich HASSE das Erheben der Daten. Die ersten paar Bücher war ich noch so begeistert, dass ich sie gleich nach dem Lesen eingepflegt habe. Ich merkte, wie ich das immer weiter herauszögerte. Ich machte es nur einmal die Woche, dann einmal im Monat, wenn ich eh am Rückblick arbeite … Und dann mal eben zwei Monate gar nicht mehr. Aber wenn ich das herauszögerte, war ich mir bei den Antworten hinterher gar nicht mehr so sicher. Ich konnte mich nicht erinnern. War da jetzt jemand offen neurodivers, erkennbar daran, dass man seine Art, Reize zu verarbeiten oder Ähnliches zu lesen bekam und sie sich von den Anderen unterschied? War da ein Charakter, bei dem klar an Namen oder Beschreibung erkennbar war, dass er nicht weiß war? Wenn ich danach schon zehn weitere Bücher gelesen habe, hatte ich das hier nicht mehr frisch in Erinnerung und so passieren womöglich Fehler in der Statistik.
 Aber noch ein Problem gab es mit der schieren Masse an Variablen, die ich erhob: Ich sah den Wald vor lauter Bäumen nicht. Beim Scrollen konnte es offenbar sehr leicht passieren, dass ich einen nötigen Klick übersah. Und das sieht man dann leider erst bei den Statistiken, die Google einem selbst ausgibt. Und die man für manche Sachen schon nutzen könnte, ohne erst über Stata zu gehen, WENN MAN NICHT EINE IDIOTIN WÄRE UND EINEN KLICK VERGESSEN HÄTTE, WESHALB EINE ANTWORT FEHLT.
Aber noch ein Problem gab es mit der schieren Masse an Variablen, die ich erhob: Ich sah den Wald vor lauter Bäumen nicht. Beim Scrollen konnte es offenbar sehr leicht passieren, dass ich einen nötigen Klick übersah. Und das sieht man dann leider erst bei den Statistiken, die Google einem selbst ausgibt. Und die man für manche Sachen schon nutzen könnte, ohne erst über Stata zu gehen, WENN MAN NICHT EINE IDIOTIN WÄRE UND EINEN KLICK VERGESSEN HÄTTE, WESHALB EINE ANTWORT FEHLT.
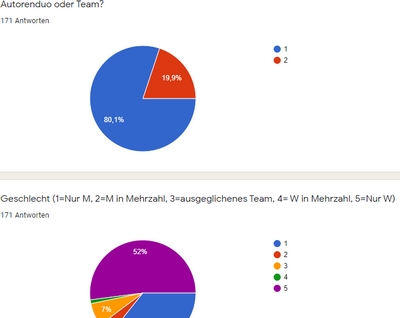
Denn, wie man sieht, sind die Statistiken eigentlich ganz hübsch, die Google einem hier angeben kann. Wenn man nur eine einzelne Variable betrachtet, wie Rating, oder, wie hier, ob es Autorenteams oder einzelne Autoren (und in welcher Geschlechtsverteilung) sind, kann man gleich mit den Ergebnissen arbeiten, die Google einem gibt, ohne, dass man auch nur einen Finger rühren muss. Aber leider kann man die Antworten hinterher nur in der Tabelle überarbeiten – und die ist nur ein Export hinterher und hat keinen Einfluss mehr auf auf die hübschen Tortendiagramme. Weshalb es zwingend notwendig ist, keine Antwort zu übersehen, wenn man damit arbeiten will. Seufz!
Was ich besser machen muss
Aber noch ein Problem gibt es: Ich habe immer noch nicht genug Variablen. Was mich zu den Dingen führt, die ich für 2020 verändern muss:
- Ich brauche die Variable: ‚Klobuch‘ oder nicht. Denn die verzerren so ziemlich meine Lesegeschwindigkeit. Sie sind ja dafür gedacht, dass ich sie langsam lese. Alleine schon, weil ich kaum Bücher habe, die ich im Bad ertrage (ohne Mensch auf dem Cover, ohne Autorenbild, ohne Werbung innen drin für Bücher mit Menschen auf dem Cover, …). Aber wenn ich hier 60 Tage pro Buch brauche, und sonst 1-3 und ich keine Möglichkeit habe, sie rauszurechnen, dann hab ich kein korrektes Ergebnis über meine wirklichen Seiten pro Tag, etc.
- Ich muss mir eingestehen, dass der Plan, nur die tatsächlich gelesenen Seiten einzutragen, gescheitert ist. Denn eigentlich wollte ich nur die Seiten zählen, die ich wirklich lese, was bedeutet, teils Vorwörter, Leseproben, Werbung, etc. rausrechnen zu müssen. Das geht aber schwer, wenn man das Buch längst weggegeben hat, wenn man sich endlich an die Statistik setzt. Hier muss ich mir ein anderes System überlegen – und sei es nur, halt alle Druckseiten zu zählen -, und das vor allem auch durchgängig beizubehalten, damit ich nicht mit zwei oder mehr verschiedenen Zählweisen meine Statistik verzerre.
- Es müssen Variablen gekürzt werden, damit meine Motivation wieder da ist. Es war ein schöner Gedanke, alle Genres einzeln zu erheben, so, dass Bücher auch 5 und mehr angehören können, aber das macht den Fragebogen zu einem Monster – und zu etwas, wobei man Antwortfelder übersieht. In Zukunft werde ich nur zwei Haupt- und Zweitgenre erheben und da jeder Möglichkeit eine Zahl zuordnen (weil Stata sich ansonsten weigert, einige Dinge zu erheben).
- Jede Antwort muss Pflicht sein. Das bedeutet mehr Aufwand bei der Erstellung des Fragebogens, aber ich muss es so einstellen, dass ich ihn nicht abschicken kann, wenn nicht jede Frage beantwortet ist.
- Eine dritte Geschlechtsmöglichkeit für den Autor muss her. Ich hatte zwar noch nie einen nonbinären Autor – zumindest stand es nie direkt im Buch und ich recherchiere die Autoren weder vorher noch hinterher -, aber rein der Vollständigkeit halber muss es dringend sein, finde ich. Vielleicht läuft mir ja doch ein Buch über den Weg, das mir selbst sagt: „Hey, mein Autor ist nonbinär oder genderfluid.“
- Ich muss endlich dran denken, das Buch sofort einzutragen. Spätestens am nächsten Tag. Keine Faulheit mehr!
- Irgendwie würde ich gern auch die Abbruch-Bücher erheben, weil Goodreads da keine Daten anzeigt. Wenn ich sie aber mit in diese, Fragebogen nehme, kann ich wieder die Google-Diagramme nicht verwenden und muss sie in jeder Tabelle erst rausrechnen (lassen, zum Glück kann Stata sowas echt gut). Hier muss ich mir mal eine Möglichkeit überlegen.
Das wird eine Menge Arbeit. Aber ich bin nun einmal einfach noch nicht zufrieden.
Welche Statistik nutzt ihr? Macht ihr überhaupt eine? Und habe ich Variablen vergessen, die vielleicht noch nützlich oder spannend wären? Nur raus damit.